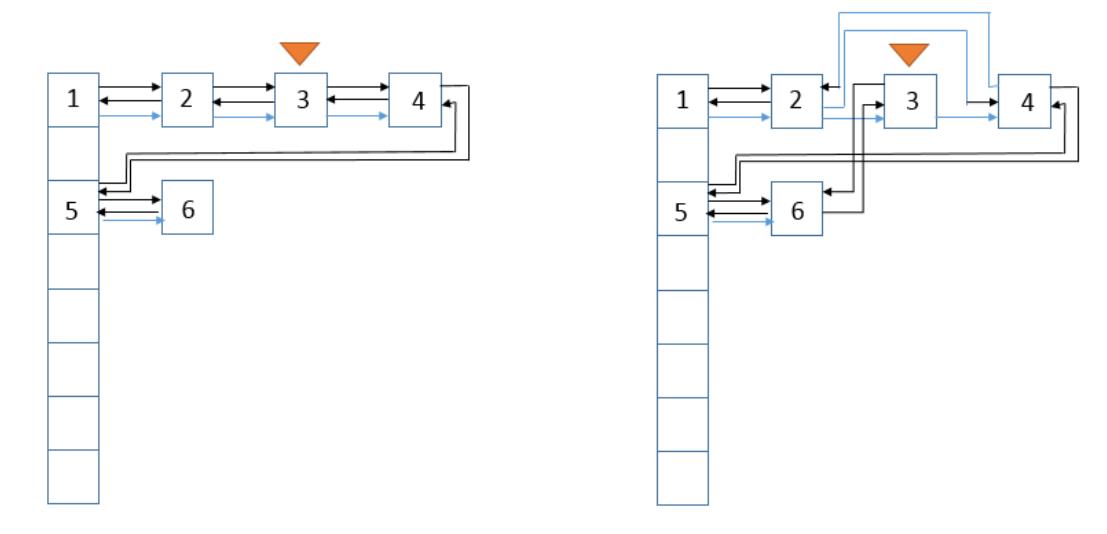
voidafterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; //根据调用前的代码可以看出,次数的条件为accessOrder == true 且 添加的数据的key在原来的Map中存在,且访问的节点不是双向链表尾节点 // 因此这个条件可以看为如果accessOrder == true将更新的节点放至双向链表尾部 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //将节点的后节点置为空 p.after = null; //如果原节点为头节点,则将后节点变为头节点 if (b == null) head = a; else // 将当前节点的前节点的后节点指向当前节点的后节点 b.after = a; if (a != null) // 将当前节点的后节点的前节点指向当前节点的前节点 a.before = b; else last = b; // 以上操作将当前节点从双向列表中取出 // 将当前节点添加至双向列表尾部 if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
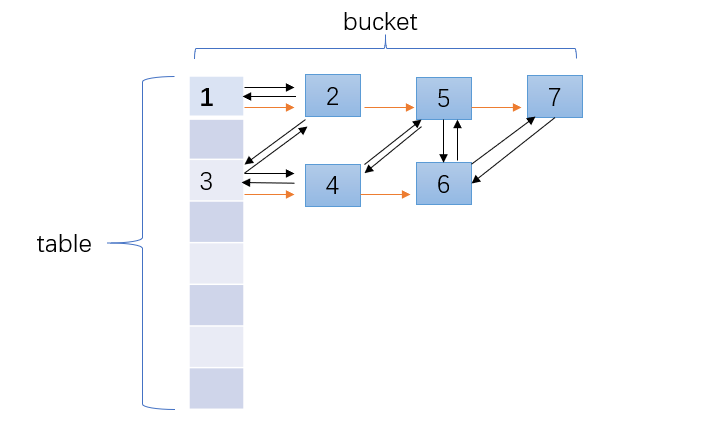
具象化数据结构如下:
get
1 2 3 4 5 6 7 8
public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null) returnnull; if (accessOrder) afterNodeAccess(e); return e.value; }
当accessOrder为true时, 也会讲取得的节点放到链表末尾
containsValue
1 2 3 4 5 6 7 8
publicbooleancontainsValue(Object value) { for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { Vv= e.value; if (v == value || (value != null && value.equals(v))) returntrue; } returnfalse; }