写在最前面   这是我JDK源码学习系列的第一篇博文,我知道源码学习这条路很难坚持,但是我始终相信,不积跬步无以至千里。初步计划是每天早上晨会前看一个类的源码,虽然工作比较忙,但时间就像那个,挤挤总是有的嘛~~晚上回来写写博文,一是加深理解二来也加深记忆方便以后查阅。学习的步骤当然是先从自己已经用的非常熟练的类入手。
java.lang.String 1 2 3 4 public final class String implements java .io.Serializable, Comparable<String>, CharSequence
String 是final修饰的类,不可以被继承,可以被序列化,实现了Comparable, CharSequence接口
成员变量 1 2 3 4 private final char value[];private int hash; private static final long serialVersionUID = -6849794470754667710L ;private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField [0 ];
String是以字符数组的形式实现的,有final关键字修饰,说明字符串一旦初始化就不可修改。这也是与其与StringBuffer和StringBuilder的区别。hash则用来存放计算后的哈希值。
构造函数 无参构造 1 2 3 public String () { this .value = "" .value; }
构造一个长度为0的字符串,由于String是不可变的,没什么大用。但是String s =""和String s2 == new String()有显著区别:前者对象存储在常量池,后者存储在堆中。因此是s == s2返回false
String参数 1 2 3 4 public String (String original) { this .value = original.value; this .hash = original.hash; }
char[]参数 1 2 3 public String (char value[]) { this .value = Arrays.copyOf(value, value.length); }
Arrays.copyOf方法中新建了一个char数组,并将value中的值复制入新建的数组中,返回对新建数组的引用,this.value指向这个新建的数组。参数数组改变时字符串不会变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public String (char value[], int offset, int count) { if (offset < 0 ) { throw new StringIndexOutOfBoundsException (offset); } if (count <= 0 ) { if (count < 0 ) { throw new StringIndexOutOfBoundsException (count); } if (offset <= value.length) { this .value = "" .value; return ; } } if (offset > value.length - count) { throw new StringIndexOutOfBoundsException (offset + count); } this .value = Arrays.copyOfRange(value, offset, offset+count); }
同上,调用Arrays.copyOfRange新建了一个char数组,进行对value进行截取复制。传回引用至this.value。
byte[] 1 2 3 4 5 6 7 8 public String (byte bytes[], int offset, int length) { checkBounds(bytes, offset, length); this .value = StringCoding.decode(bytes, offset, length); } public String (byte bytes[]) { this (bytes, 0 , bytes.length); }
StringBuilder和StringBuffer参数 1 2 3 4 5 6 7 8 9 public String (StringBuffer buffer) { synchronized (buffer) { this .value = Arrays.copyOf(buffer.getValue(), buffer.length()); } } public String (StringBuilder builder) { this .value = Arrays.copyOf(builder.getValue(), builder.length()); }
原理类似于char[]参数的构造函数
重要方法 length 1 2 3 public int length () { return value.length; }
获取字符串中包含的字符数, 即字符数组的长度
isEmpty 1 2 3 public boolean isEmpty () { return value.length == 0 ; }
判断字符串是否为空,即判断value数组的长度为0即可
charAt 1 2 3 4 5 6 public char charAt (int index) { if ((index < 0 ) || (index >= value.length)) { throw new StringIndexOutOfBoundsException (index); } return value[index]; }
返回数组index下标处的字符
codePointAt、codePointBefore、 codePointRange 暂时还未理解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public int codePointAt (int index) { if ((index < 0 ) || (index >= value.length)) { throw new StringIndexOutOfBoundsException (index); } return Character.codePointAtImpl(value, index, value.length); } public int codePointBefore (int index) { int i = index - 1 ; if ((i < 0 ) || (i >= value.length)) { throw new StringIndexOutOfBoundsException (index); } return Character.codePointBeforeImpl(value, index, 0 ); } public int codePointCount (int beginIndex, int endIndex) { if (beginIndex < 0 || endIndex > value.length || beginIndex > endIndex) { throw new IndexOutOfBoundsException (); } return Character.codePointCountImpl(value, beginIndex, endIndex - beginIndex); }
getChars 1 2 3 4 void getChars (char dst[], int dstBegin) { System.arraycopy(value, 0 , dst, dstBegin, value.length); }
此方法AbstractStringBuilder类中用到
1 2 3 4 5 6 7 8 9 10 11 12 13 public void getChars (int srcBegin, int srcEnd, char dst[], int dstBegin) { if (srcBegin < 0 ) { throw new StringIndexOutOfBoundsException (srcBegin); } if (srcEnd > value.length) { throw new StringIndexOutOfBoundsException (srcEnd); } if (srcBegin > srcEnd) { throw new StringIndexOutOfBoundsException (srcEnd - srcBegin); } System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); }
getBytes 1 2 3 4 5 6 7 8 9 10 11 public byte [] getBytes(String charsetName) throws UnsupportedEncodingException { if (charsetName == null ) throw new NullPointerException (); return StringCoding.encode(charsetName, value, 0 , value.length); } public byte [] getBytes() { return StringCoding.encode(value, 0 , value.length); }
equals、contentEquals 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public boolean equals (Object anObject) { if (this == anObject) { return true ; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0 ; while (n-- != 0 ) { if (v1[i] != v2[i]) return false ; i++; } return true ; } } return false ; } public boolean equalsIgnoreCase (String anotherString) { return (this == anotherString) ? true : (anotherString != null ) && (anotherString.value.length == value.length) && regionMatches(true , 0 , anotherString, 0 , value.length); }
String类的equals方法首先比较两个字符串是否为同一个对象,为否的话继续遍历比较两个字符串对象内的char数组是否完全相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public boolean contentEquals (StringBuffer sb) { return contentEquals((CharSequence)sb); } public boolean contentEquals (CharSequence cs) { if (cs instanceof AbstractStringBuilder) { if (cs instanceof StringBuffer) { synchronized (cs) { return nonSyncContentEquals((AbstractStringBuilder)cs); } } else { return nonSyncContentEquals((AbstractStringBuilder)cs); } } if (cs instanceof String) { return equals(cs); } char v1[] = value; int n = v1.length; if (n != cs.length()) { return false ; } for (int i = 0 ; i < n; i++) { if (v1[i] != cs.charAt(i)) { return false ; } } return true ; } private boolean nonSyncContentEquals (AbstractStringBuilder sb) { char v1[] = value; char v2[] = sb.getValue(); int n = v1.length; if (n != sb.length()) { return false ; } for (int i = 0 ; i < n; i++) { if (v1[i] != v2[i]) { return false ; } } return true ; }
contentEquals 效果与equals类似, 不过equals参数为String而contentEquals参数为CharSequence及其子类如CharBuffer, Segment, String, StringBuffer, StringBuilder
comapreTo 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public int compareTo (String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0 ; while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; if (c1 != c2) { return c1 - c2; } k++; } return len1 - len2; }
比较两个字符串的大小,先顺序遍历两个字符串的char数组,如果有不相等的字符,则返回结果。否则则比较两个字符串的长度。
大小写不敏感的比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public static final Comparator<String> CASE_INSENSITIVE_ORDER = new CaseInsensitiveComparator (); private static class CaseInsensitiveComparator implements Comparator <String>, java.io.Serializable { private static final long serialVersionUID = 8575799808933029326L ; public int compare (String s1, String s2) { int n1 = s1.length(); int n2 = s2.length(); int min = Math.min(n1, n2); for (int i = 0 ; i < min; i++) { char c1 = s1.charAt(i); char c2 = s2.charAt(i); if (c1 != c2) { c1 = Character.toUpperCase(c1); c2 = Character.toUpperCase(c2); if (c1 != c2) { c1 = Character.toLowerCase(c1); c2 = Character.toLowerCase(c2); if (c1 != c2) { return c1 - c2; } } } } return n1 - n2; } private Object readResolve () { return CASE_INSENSITIVE_ORDER; } } public int compareToIgnoreCase (String str) { return CASE_INSENSITIVE_ORDER.compare(this , str); }
比较两个字符是否大小写不敏感的相等需要toUpperCase,toLowerCase同时相等。例如下例两个不相等的字符toUpperCase,toLowerCase的比较结果可能不一致
1 2 3 4 5 char ch1 = (char ) 73 ; char ch2 = (char ) 304 ; System.out.println(ch1==ch2); System.out.println(Character.toUpperCase(ch1)==Character.toUpperCase(ch2)); System.out.println(Character.toLowerCase(ch1)==Character.toLowerCase(ch2));
输出:
regionMatches 比较两个字符串中指定区域的子串是否相等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 public boolean regionMatches (int toffset, String other, int ooffset, int len) { char ta[] = value; int to = toffset; char pa[] = other.value; int po = ooffset; if ((ooffset < 0 ) || (toffset < 0 ) || (toffset > (long )value.length - len) || (ooffset > (long )other.value.length - len)) { return false ; } while (len-- > 0 ) { if (ta[to++] != pa[po++]) { return false ; } } return true ; } public boolean regionMatches (boolean ignoreCase, int toffset, String other, int ooffset, int len) { char ta[] = value; int to = toffset; char pa[] = other.value; int po = ooffset; if ((ooffset < 0 ) || (toffset < 0 ) || (toffset > (long )value.length - len) || (ooffset > (long )other.value.length - len)) { return false ; } while (len-- > 0 ) { char c1 = ta[to++]; char c2 = pa[po++]; if (c1 == c2) { continue ; } if (ignoreCase) { char u1 = Character.toUpperCase(c1); char u2 = Character.toUpperCase(c2); if (u1 == u2) { continue ; } if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) { continue ; } } return false ; } return true ; }
测试:
1 2 3 4 String s1= “tsinghua” String s2=“it is TsingHua”; s1.regionMatches(0 ,s2,6 ,7 ); s1.regionMatches(true ,0 ,s2,6 ,7 );
startWith、 endWith 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public boolean startsWith (String prefix) { return startsWith(prefix, 0 ); } public boolean endsWith (String suffix) { return startsWith(suffix, value.length - suffix.value.length); } public boolean startsWith (String prefix, int toffset) { char ta[] = value; int to = toffset; char pa[] = prefix.value; int po = 0 ; int pc = prefix.value.length; if ((toffset < 0 ) || (toffset > value.length - pc)) { return false ; } while (--pc >= 0 ) { if (ta[to++] != pa[po++]) { return false ; } } return true ; }
hashCode 1 2 3 4 5 6 7 8 9 10 11 12 13 public int hashCode () { int h = hash; if (h == 0 && value.length > 0 ) { char val[] = value; for (int i = 0 ; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
首次调用时会根据char字符数组计算哈希值:31^(n-1) + s1 31^(n-2) + … + s[n-1] i=32 i-i=(i5)-i,这种位移与减法结合的计算相比一般的运算快很多。
indexOf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public int indexOf (int ch, int fromIndex) { final int max = value.length; if (fromIndex < 0 ) { fromIndex = 0 ; } else if (fromIndex >= max) { return -1 ; } if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) { final char [] value = this .value; for (int i = fromIndex; i < max; i++) { if (value[i] == ch) { return i; } } return -1 ; } else { return indexOfSupplementary(ch, fromIndex); } } public int indexOf (int ch) { return indexOf(ch, 0 ); } public int indexOf (String str) { return indexOf(str, 0 ); } public int indexOf (String str, int fromIndex) { return String.indexOf(value, 0 , count, str, fromIndex); }
subString 1 2 3 4 5 6 7 8 9 10 11 public String substring (int beginIndex) { if (beginIndex < 0 ) { throw new StringIndexOutOfBoundsException (beginIndex); } int subLen = value.length - beginIndex; if (subLen < 0 ) { throw new StringIndexOutOfBoundsException (subLen); } return (beginIndex == 0 ) ? this : new String (value, beginIndex, subLen); }
当参数为0时,返回this,不会新建String;另由构造函数内调用的Arrays.copyOfRange()方法可知截取后的字符串包括下标为beginIndex的字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public String substring (int beginIndex, int endIndex) { if (beginIndex < 0 ) { throw new StringIndexOutOfBoundsException (beginIndex); } if (endIndex > value.length) { throw new StringIndexOutOfBoundsException (endIndex); } int subLen = endIndex - beginIndex; if (subLen < 0 ) { throw new StringIndexOutOfBoundsException (subLen); } return ((beginIndex == 0 ) && (endIndex == value.length)) ? this : new String (value, beginIndex, subLen); } public CharSequence subSequence (int beginIndex, int endIndex) { return this .substring(beginIndex, endIndex); }
concat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public String concat (String str) { int otherLen = str.length(); if (otherLen == 0 ) { return this ; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); return new String (buf, true ); } void getChars (char dst[], int dstBegin) { System.arraycopy(value, 0 , dst, dstBegin, value.length); }
分析以上代码可知concat方法的作用为在字符串后拼接字符串,返回的字符串及字符串数组为新对象
replace 该replace方法参数是char,源码思路是找到第一个出现的oldChar,如果oldChar的下标小于len的下标,把oldChar前面的存到临时变量buf中,把oldChar后面的所有oldChar都变为newChar.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public String replace (char oldChar, char newChar) { if (oldChar != newChar) { int len = value.length; int i = -1 ; char [] val = value; while (++i < len) { if (val[i] == oldChar) { break ; } } if (i < len) { char buf[] = new char [len]; for (int j = 0 ; j < i; j++) { buf[j] = val[j]; } while (i < len) { char c = val[i]; buf[i] = (c == oldChar) ? newChar : c; i++; } return new String (buf, true ); } } return this ; }
借用正则表达式的replace:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public String replaceFirst (String regex, String replacement) { return Pattern.compile(regex).matcher(this ).replaceFirst(replacement); } public String replaceAll (String regex, String replacement) { return Pattern.compile(regex).matcher(this ).replaceAll(replacement); } public String replace (CharSequence target, CharSequence replacement) { return Pattern.compile(target.toString(), Pattern.LITERAL).matcher( this ).replaceAll(Matcher.quoteReplacement(replacement.toString())); }
其他用到了正则的String方法
1 2 3 public boolean matches (String regex) { return Pattern.matches(regex, this ); }
split 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public String[] split(String regex) { return split(regex, 0 ); } public String[] split(String regex, int limit) { char ch = 0 ; if (((regex.value.length == 1 && ".$|()[{^?*+\\" .indexOf(ch = regex.charAt(0 )) == -1 ) || (regex.length() == 2 && regex.charAt(0 ) == '\\' && (((ch = regex.charAt(1 ))-'0' )|('9' -ch)) < 0 && ((ch-'a' )|('z' -ch)) < 0 && ((ch-'A' )|('Z' -ch)) < 0 )) && (ch < Character.MIN_HIGH_SURROGATE || ch > Character.MAX_LOW_SURROGATE)) { int off = 0 ; int next = 0 ; boolean limited = limit > 0 ; ArrayList<String> list = new ArrayList <>(); while ((next = indexOf(ch, off)) != -1 ) { if (!limited || list.size() < limit - 1 ) { list.add(substring(off, next)); off = next + 1 ; } else { list.add(substring(off, value.length)); off = value.length; break ; } } if (off == 0 ) return new String []{this }; if (!limited || list.size() < limit) list.add(substring(off, value.length)); int resultSize = list.size(); if (limit == 0 ) { while (resultSize > 0 && list.get(resultSize - 1 ).length() == 0 ) { resultSize--; } } String[] result = new String [resultSize]; return list.subList(0 , resultSize).toArray(result); } return Pattern.compile(regex).split(this , limit); }
分段解析:
1 2 3 4 5 6 7 8 9 if (((regex.value.length == 1 && ".$|()[{^?*+\\" .indexOf(ch = regex.charAt(0 )) == -1 ) || (regex.length() == 2 && regex.charAt(0 ) == '\\' && (((ch = regex.charAt(1 ))-'0' )|('9' -ch)) < 0 && ((ch-'a' )|('z' -ch)) < 0 && ((ch-'A' )|('Z' -ch)) < 0 )) && (ch < Character.MIN_HIGH_SURROGATE || ch > Character.MAX_LOW_SURROGATE))
1.
1 2 3 4 5 6 7 ((regex.value.length == 1 && ".$|()[{^?*+\\" .indexOf(ch = regex.charAt(0 )) == -1 ) || (regex.length() == 2 && regex.charAt(0 ) == '\\' && (((ch = regex.charAt(1 ))-'0' )|('9' -ch)) < 0 && ((ch-'a' )|('z' -ch)) < 0 && ((ch-'A' )|('Z' -ch)) < 0 ))
1. regex只有一位,且不为列出的特殊字符;
2. regex有两位,第一位为转义字符且第二个字符为非ASCII码字母或非ASCII码数字
以上两条至少一条为true
2.
1 2 (ch < Character.MIN_HIGH_SURROGATE || ch > Character.MAX_LOW_SURROGATE)
regex参数超过2个字符并且为合法的正则表达式 ?????
contains 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public boolean contains (CharSequence s) { return indexOf(s.toString()) > -1 ; } public int indexOf (String str) { return indexOf(str, 0 ); } public int indexOf (String str, int fromIndex) { return indexOf(value, 0 , value.length, str.value, 0 , str.value.length, fromIndex); } static int indexOf (char [] source, int sourceOffset, int sourceCount, char [] target, int targetOffset, int targetCount, int fromIndex) { if (fromIndex >= sourceCount) { return (targetCount == 0 ? sourceCount : -1 ); } if (fromIndex < 0 ) { fromIndex = 0 ; } if (targetCount == 0 ) { return fromIndex; } char first = target[targetOffset]; int max = sourceOffset + (sourceCount - targetCount); for (int i = sourceOffset + fromIndex; i <= max; i++) { if (source[i] != first) { while (++i <= max && source[i] != first); } if (i <= max) { int j = i + 1 ; int end = j + targetCount - 1 ; for (int k = targetOffset + 1 ; j < end && source[j] == target[k]; j++, k++); if (j == end) { return i - sourceOffset; } } } return -1 ; }
判断字符串内是否存在某字符串片段
trim 1 2 3 4 5 6 7 8 9 10 11 12 13 public String trim () { int len = value.length; int st = 0 ; char [] val = value; while ((st < len) && (val[st] <= ' ' )) { st++; } while ((st < len) && (val[len - 1 ] <= ' ' )) { len--; } return ((st > 0 ) || (len < value.length)) ? substring(st, len) : this ; }
这个trim()是去掉首尾的空格,而实现方式也非常简单,分别找到第一个非空格字符的下标,与最后一个非空格字符的下标
不可变String   String对象是不可变的。根据String源码,类中每一个看似会修改String值的方法,实际上都是创建了一个新的String对象,而最初的String对象丝毫未动:
1 2 3 4 5 public static void main (String[] args) { String a = new String ("aaaaa" ); String b = a.toUpperCase(); System.out.println(a); }
重载“+” 与 StringBuilder 重载“+”   “+”在用于String类时,会被赋予特殊的含义。
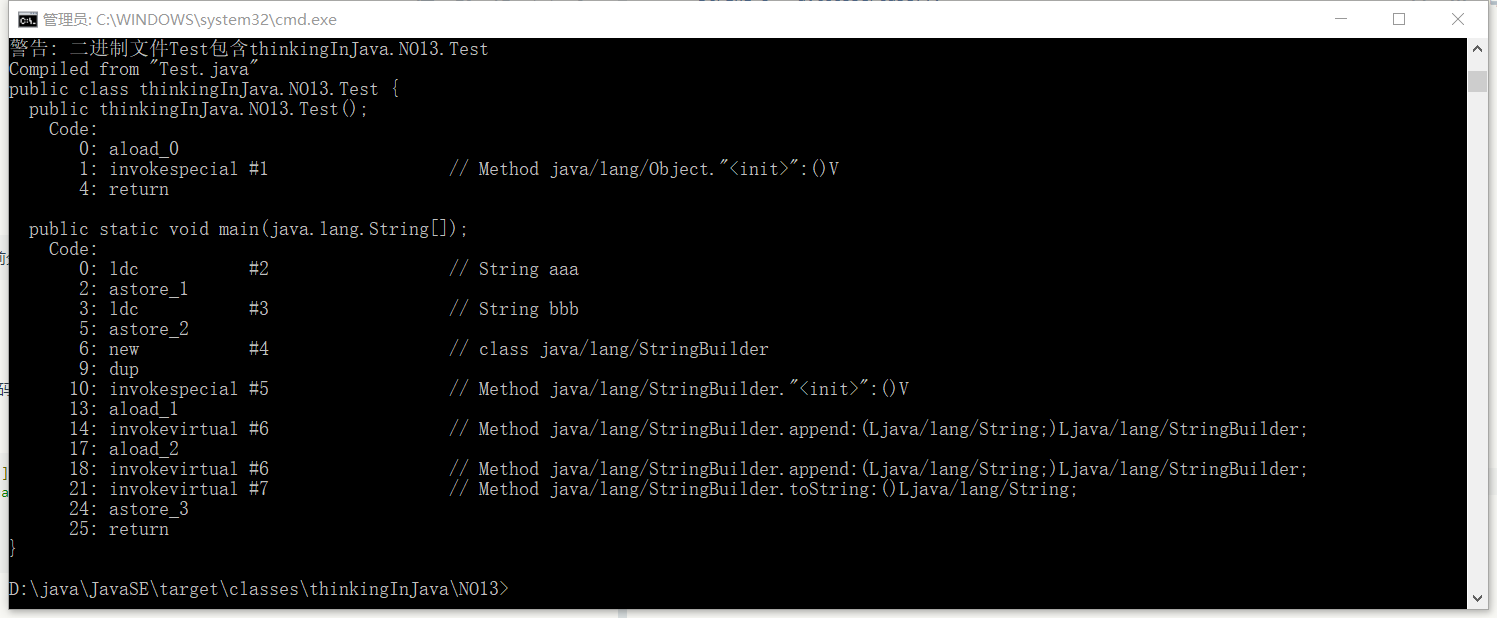
1 2 3 4 5 public static void main (String[] args) { String a = "aaa" ; String b = "bbb" ; String c = a + b; }
利用javap -c 命令反编译上述代码的class文件,得到以下结果:
可以看到生成变量c时,首先生成了一个StringBuilder类型变量,然后调用了两次append方法,在用toString方法返回String对象。只有当拼接语句中出现存储在堆中的对象时编译器才会对“+”进行重载,如果拼接语句中出现的对象全部存储在常量池,则编译器会直接对其拼接,并将结果存入常量池:
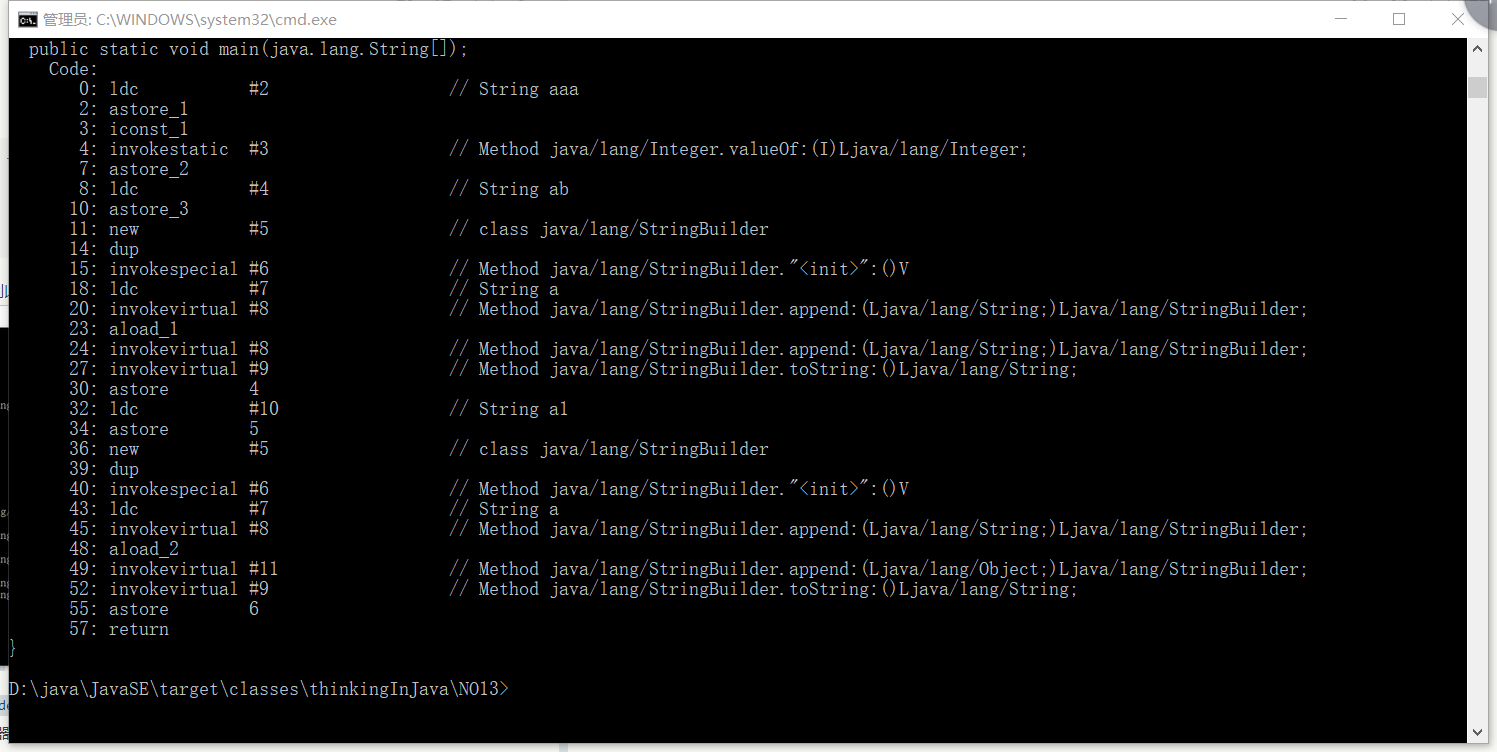
1 2 3 4 5 6 7 8 public static void main (String[] args) { String a = "aaa" ; Integer b = 1 ; String c = "a" + "b" ; String d = "a" + a; String e = "a" + 1 ; String f = "a" + b; }
反编译后结果如下:
String c = "a" + "b"和String e = "a" + 1分别对应String ab和String a1 字符串直接在常量池中相加,所得的字符串也存储在常量池中。因此如果运行
1 2 3 4 String g = "a" + "b" ;String h = "a" + 1 ;System.out.println(c == g); System.out.println(h == e);
返回的结果都是true。g,c,e,h都指向存储在常量池中。
String d = "a" + a和String f = "a" + b则对“+”进行了重载。生成新String变量存储在堆中。因此如果运行:
1 2 3 4 String i = "a" + a;String j = "a" + b;System.out.println(d == i); System.out.println(f == j);
StringBuilder的使用 这个现象让我明白以前对的字符串拼接操作的缺陷。例如
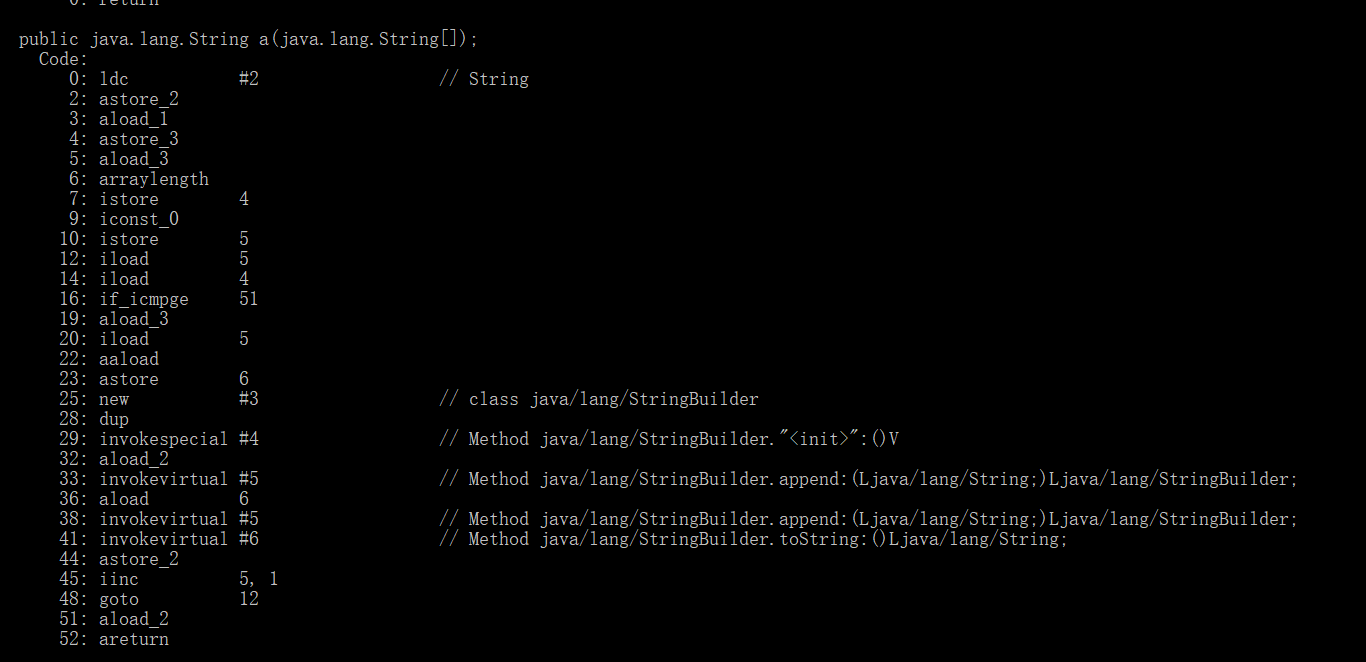
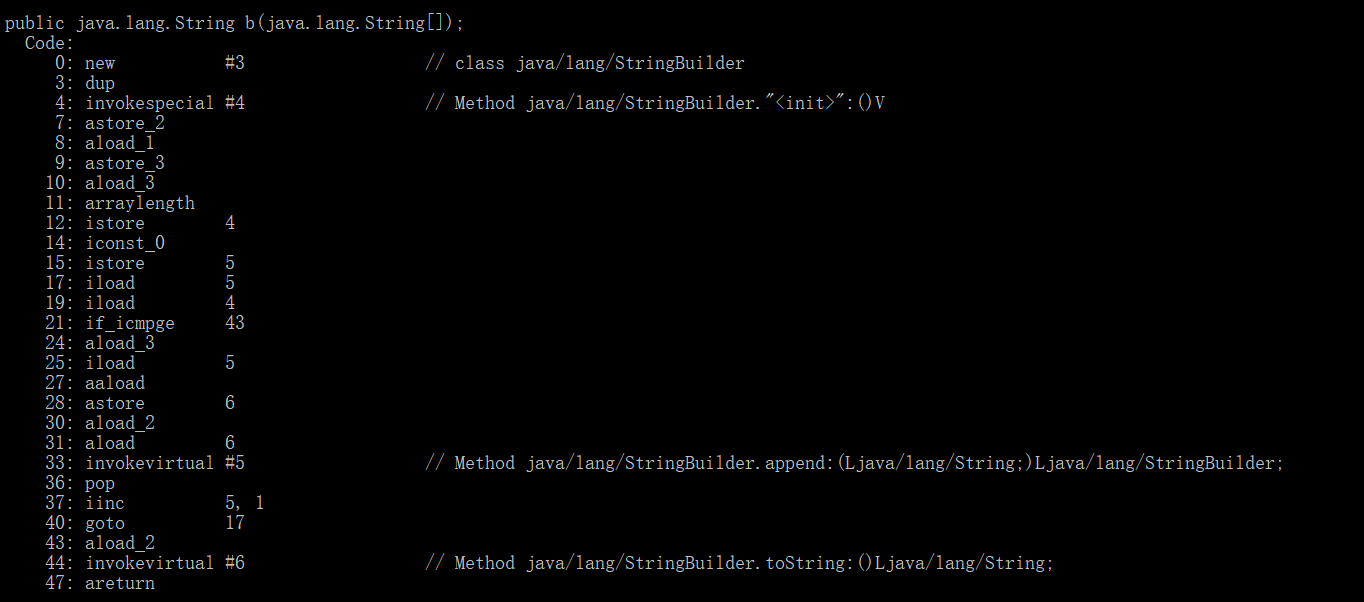
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public String a (String[] strings) { String result = "" ; for (String s : strings) { result += s; } return result; } public String b (String[] strings) { StringBuilder result = new StringBuilder (); for (String s : strings) { result.append(s); } return result.toString(); }
对这两行代码进行反编译:StringBuilder对象。这对于内存是一种浪费。因此当使用循环去拼接字符串时,最好先创建StringBuilder对象,然后使用append去实现字符串拼接。
toString方法中的递归 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class InfiniteResoursion { @Override public String toString () { return "内存地址为" + this ; } public static void main (String[] args) { List<InfiniteResoursion> infiniteResoursions = new ArrayList <>(); for (int i = 0 ; i < 10 ; i++){ infiniteResoursions.add(new InfiniteResoursion ()); } System.out.println(infiniteResoursions); } }
InfiniteResoursion的toString方法看似是打印出对象的内存地址,但是当实际运行时,却会报java.lang.StackOverflowError。这是因为当运行"内存地址为" + this时,编译器会自动调用this.toString将this转换为字符串,于是就发生了递归。如果真的想打印内存地址,则要调用Object.toString:
1 2 3 4 @Override public String toString() { return "内存地址为" + super.toString(); }
总结   源码阅读系列博文第一篇,跟了一遍String源码,但是却并不尽兴,对于内存层面的理解远没有到位。所以还得继续努力。
  既然选择远方,便只顾风雨兼程。不忘初心,方得始终。