一. HashSet概述
HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持。主要具有以下的特点:
  不保证set的迭代顺序,特别是它不保证该顺序恒久不变有且只允许一个null元素;不允许有重复元素,非同步的。
二. HashSet类结构:
1
| public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
|
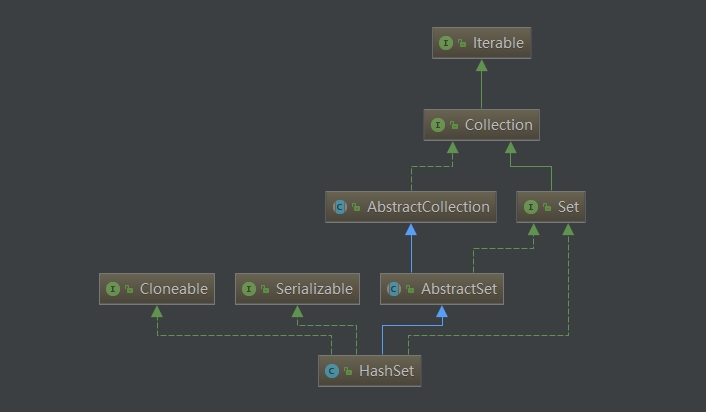
HashSet实现了Set,Cloneable,Serializable接口,继承AbstractSet抽象类。
其父类及接口如下图:
三. 成员变量
1
2
3
| private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
|
从两个成员变量可看出,HashSet底层是由HashMap(实际是HashMap和LinkedHashMap)实现数据存储的。、HashMap中的key用于存储实际的数据,value则用HashSet内定义的一个”虚拟”的static final Object对象填充。
四. 构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public HashSet() {
map = new HashMap<>();
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
|
五. 成员方法
add()
1
2
3
| public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
|
HahsSet的add()方法底层调用HashMap.put, 由HashMap源码可知:
key值可以为null; key值唯一- 如果添加时
key已存在(oldKey == newKey 或者 oldKey.equals(newKey)),key值不会被覆盖。
由此与HashSet已知特性一一对应:
HashSet可以存储null值HashSet中的元素不重复HashSet添加重复元素时不会进行替换
clear()
1
2
3
| public void clear() {
map.clear();
}
|
contains()
1
2
3
4
| // map中的containsKey 先根据key值去决定在数组中的存储下标,再遍历其中存储的链表去查找对应节点
public boolean contains(Object o) {
return map.containsKey(o);
}
|
isEmpty()
1
2
3
| public boolean isEmpty() {
return map.isEmpty();
}
|
remove()
1
2
3
4
|
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
|
size()
1
2
3
4
|
public int size() {
return map.size();
}
|
removeAll()、 addAll()、 containsAll()
这几个方法实现在AbstractCollection, 基本思想都是遍历然后调用HashSet中的remove、add、contains方法
iterator
1
2
3
| public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
|
总结
HashSet底层由HashMap实现,数据存储在HashMap的key内。HashSet可以存储null。HashSet不是线程安全的。